The subject of project management and release testing has been discussed in other topics. I am opening this topic to discuss how we implement some form of formal testing of major releases and rolling updates.
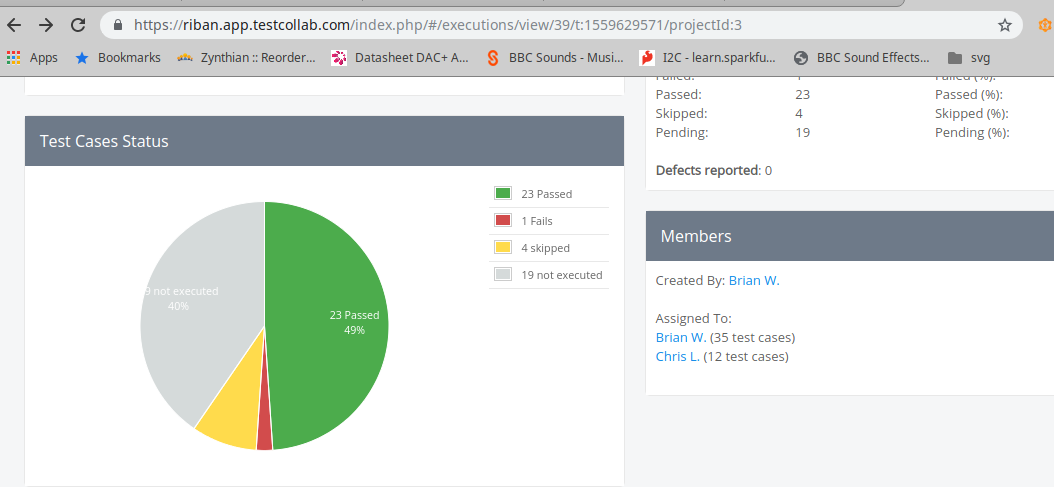
Testing is a thorny subject. It can be time consuming and formal testing can get quite tedious, especially if full test runs need to be repeated. It can also be fun and rewarding, watching those pie charts turn green :-). The purpose of the testing needs to be clear and each test should provide benefit and ideally avoid repeating elements tested elsewhere. Tests should be as atomic as possible allowing direct correlation between a requirement and its test. This ensures functionality (and other elements) are thoroughly tested without the tedious overlap.
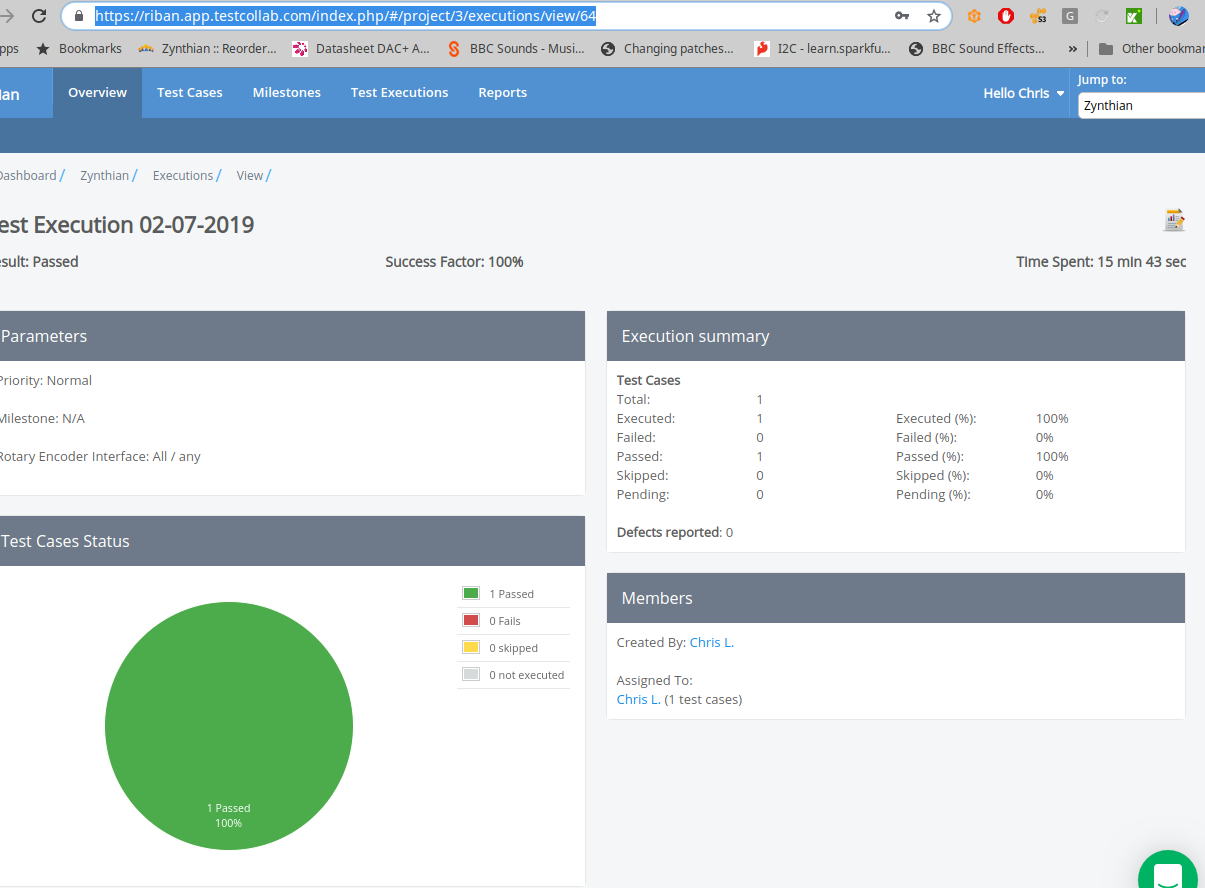
I have several years experience of managing and performing testing on software projects. I have mostly used a commercial product called TestRail to track that testing. Today I tried out Test Collab which provides a free plan with limitations (200 test cases and 400 executed cases). Much of my time today was spent trying to exceed those limits to discover the behaviour at the break point. I can report that it stops at the limit (400 executed) informing the user that they have exceeded their plan limit (and offering upgrade) but retains results to that point. Deleting previous results will allow further testing. Each project seems to have its own allocation so splitting tests across multiple projects within the same TEst Collab account also extends their offering. The product itself is similar to TestRail with slightly fewer features but is generally comparable. Test Collab supports multiple users for each account with various roles and a fair degree of customisation and integration options. (There doesn’t seem to be a limit on quantity of users for the free plan though I haven’t tested that.) Paid plans are subscription based calculated by quantity of users.
Regarding the actual testing, we should test have functional tests which test that the product functions as expected under normal conditions and non-functional tests which test other elements like where the break points are (stress testing), how long the product performs without degradation (soak testing), behaviour under higher than normal (but not excessive) load (load testing), etc.
Functional tests are basically a list of user requirements (what the product should do) written as a pair of:
- Steps to exercise the function
- Expected behaviour
Non-functional tests are similar pairs:
- Steps to trigger the test condition
- Expected behaviour
Each test is called a test case and is formed by a set of steps and the expected result.
Test cases are combined to form a test execution which has the purpose of testing a particular area or group of features, e.g. functional requirements.
Test executions are added to a Test Suite which has the purpose of testing a particular release. This may be a full set of tests for a major release like Aruk or a smaller set of tests to validate an software update.
Each test case may be assigned to a team member.
Test Collab can send emails informing team members of their allocation of tests and results of test runs. It has some reporting features. It can export and import test cases, etc. which is valuable in case it proves to be an inappropriate platform.
I believe we can probably fit our test requirements within the free plan with some careful planning.
Ideally as much testing as possible is automated but before we can think about that we need to define what the tests are and run them manually to prove they perform the required test and produce expected result data. Some tests may always need manual testing, e.g. physical tests like rotating a knob to check the encoder library works. (Someone in our community might provide a robot for this but let’s walk first). Once there is a test pack we can then start to automate elements which may start with assisted automation, e.g. a script triggers some activity then a human monitors the output. Further enhancement may lead to some fully automated tests.
As well as formal testing there is a real advantage to performing monkey testing which is basically playing with the product without a specific purpose (the fun bit). This often finds many issues that formal testing won’t find because the product gets exercised in ways that are unexpected.
I feel we need some measure of success so that we avoid endless monkey testing and vague ideas of, “That is probably about good enough” for our releases. Test suite content is driven by the milestone (another element of the test tool) and should include all the tests that measure success that signals the product is ready for release. If all tests in the test suite pass or there are failed tests which are accepted by the project manager to be follow-on actions then the product is ready.
Testing needs to be dynamic and adaptable too. If during testing you find something passes but it should fail then the test case / execution / suite needs to be updated. This can happen during execution of a test suite which can lead to a 99% passed test suite jumping to 88% passed but that is normal. The more testing that is performed the more accurate the test suites become and the less often this happens.
I am happy to start setting up some formal test monitoring if we want. Similar to issue tracking, this can seem process heavy and few people relish the prospect of formal testing but it really makes a difference to product credibility. If you consistently release good quality products then your users will stay. The converse is far truer. It is easy to lose customers through a single bad experience.
 .
.