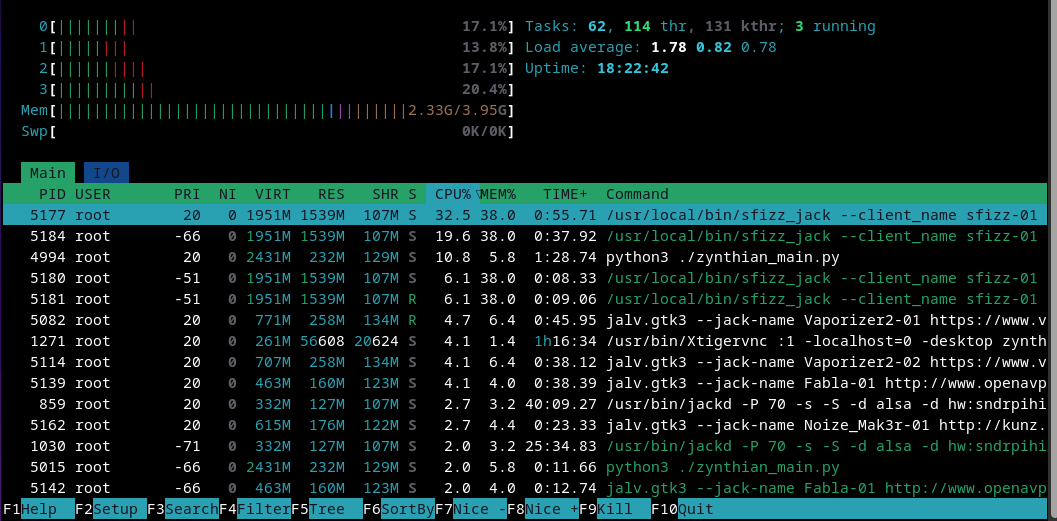
I have two versions of a piano sfz, one with velocity crossfades and one without. Using crossfades, I quickly hit the polyphony limit and it’s unusable. Is there a way to increase it? Setting it using the “polyphony” keyword in the .sfz file has no effect.
I realize there’s a limit due to CPU power, but I’d like to find out what that limit actually is (currently on my PI4, which I plan to upgrade to a PI5 and use a higher limit.)
Here’s what I do to tame the effect you report: additionally to the xf* opcodes for crossfades I also use hivel and lovel. If you don’t, any region sharing the same note value are played, even if it has no volume because of the crossfade. This way you can limit the number of simultaneously triggered notes to 2. Here’s an example:
So this group is a middle set of 5 velocity layers crossfading to each other of your very own rhodes library.
By adding the hivel and lovel opcodes, the group is not triggered at all outside velocities between 25 and 84, so these triggers to not add to the polyphony count. In your original version, each of the five groups is triggered even if it is outside the crossfade range. With this changed for a triggered midi note-on event with velocity 50 this group and the group above crossfading into it will be triggerd, but not the others-
You can also consider the note_polyphony and note_selfmask option.
This is btw. also a reason to think about if you need multipe mic samples for pianos. Let’s say you got 3 mics, 5 velocity layers with velocity crossfades (but not limited) then you hit 15 regions with each key.
Wow, thanks! Looking forward to trying this. I’ll see if that’s documented at sfzformat.com , and whether sforzando and linuxsampler work the same way.
I would love to know that as well. Since I rarely use sforzando on my desktop and found linuxsampler on zynthian behaving weird I just exclusively used sfizz and only know how this handles some stuff.
Otherwise, speaking of weirdo, the opcode set of sfizz is quite rich, but lacks sometimes in fields you didn’t expect.
Not just for pi5. When using sfizz standalone on pi4 I didn’t see this issue, IIRC. (I’ll verify this later.) Perhaps the 21 voice limit was for Pi3?
Personally, I think the hard limit should be significantly higher, and all built-in sfz’s could use a limit so that out of the box it works fine, but folks can override it and they can set whatever limit they want for sfz’s they import.
Maybe at some point I’ll bite the bullet and set up to build Zynthian, or at least, build sfizz for Zynthian and import it, and experiment.
Anyway, I’ll file an issue, and thanks big time for the insights!
I tried adding the lovel and hivel opcodes and bingo, it works! Thanks big time for that hint!
I think it’s a bug in sfizz: a voice that’s too low to fade in shouldn’t be playing. Later I’ll try it with linuxsampler, and maybe sforzando (on Windows) too.
Great it worked for you. For velocity based crossfades it certainly should act like you propose. Maybe they just implemented all these functions together and alike, because for CC based crossfades it makes totally sense to play outside the crossfade.
I’ve been making some tests and trying to optimize the parameters of sfizz, specially the “num_voices” and “preload_size” parameters.
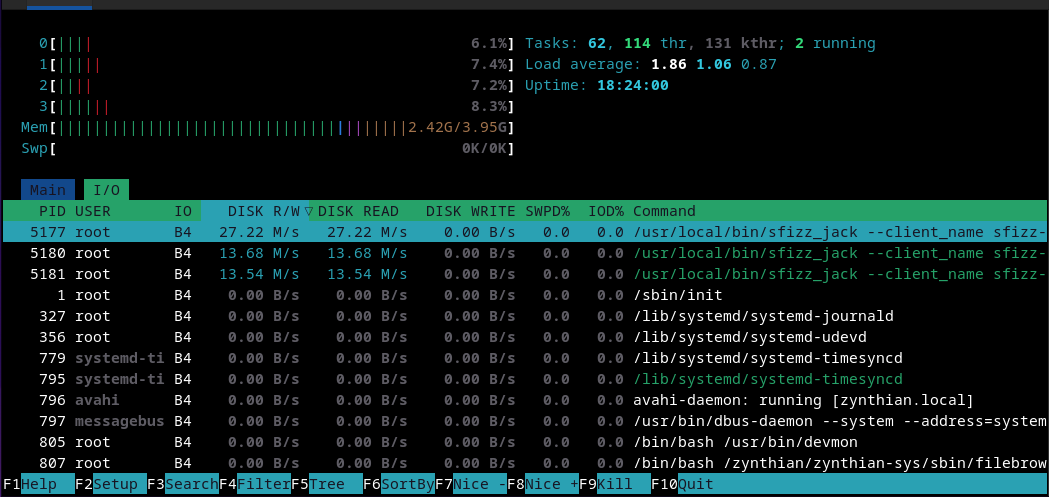
I tested with Salamander V3 and a random pattern that generates lots of notes in all the range with random velocities and the sustain pedal pushed all the time. It was a really hard test and i got Xruns due to bottleneck in disk access (SD-card):
It would increase polyphony in RPi5 while keeping current behavior for RPi4 and slighty reduce polyphony for Pi3. I didn’t test with Pi3, so it should be confirmed this reduction is enough to avoid XRuns or it needs still more reduction in polyphony limit.
Somebody tested it with hint_ram_based=1 in the sfz script? Would be interesting, because it sounds like the sd speed is the bottleneck on either version of the PI then, right?
Disk is not being used at all and as i said, no XRUNs at all. It plays super-smoothly. I could probably increase polyphony a lot more than 64 without getting XRUNs.
BTW, this is the pattern used, with velocity humanization set to 100% and sustain ON all the time:
Not a joke!
As i told in the post above, the same pattern played without the hint_ram_based=1 generated lot of XRUNs not matter the preload_size value i tried.
I’m not 100% sure what the preload_size parameter really is, but I guess it means it would load samples smaller than that into ram?
Never saw the data size unit “number of floats” before, but when it is what I think, its 8192 * 4 Bytes = 32768 Bytes? Other comment says “bytes”, so 8192.
Do you know there is an option in sfizz to just load libraries to RAM in any case? This could be the default behavior for our use case (fast cpu, slow sd card), at least, if the soundfont doesn’t exceed the available ram.
As far as i know, there is no such option, but we could implement it quite easily by injecting the “hint_ram_based” op code on-the-fly.
The problem is it takes a live to load big soundfonts. It’s really annoying. We could work around preset preloading to use streamed-loading and then, when asserting the soundfont, load full to RAM, but as i told, it takes a lot of time for big soundfonts, and it block the engine process until this is done. No progress indication. Just a frozen process until loading is finished.
Perhaps we should use smaller soundfonts in the Factory Collection, and warn against big ones, explaining that they require a NVMe disk to perform without XRUNs.
Anyway, think the test i ran is really overkill and probably far from most real use-cases. It could be wise to test with some “Rachmaninoff” mid files instead.
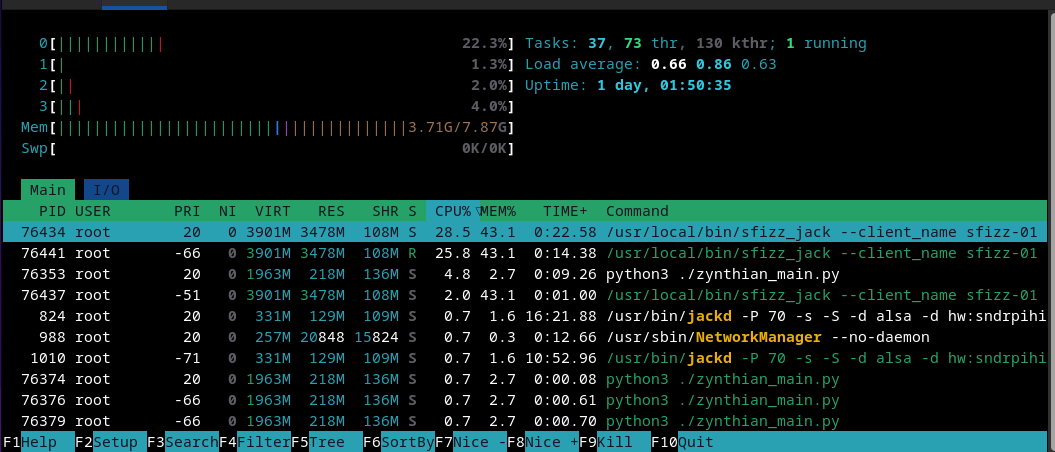
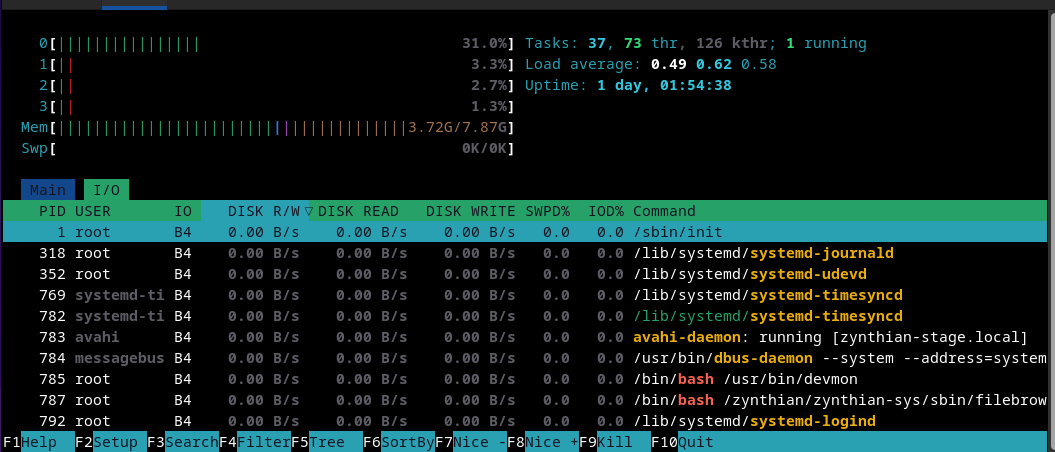
More tests. I just repeated the initial test with Salamander Grand Piano, normal stream-loading (no hint_ram_based option). I used another V5, with same SD-card (same model and branch) but 8GB RBPi instead of the 4GB RBPi i used for the first test.
I must say i’m surprised because it improves a lot. XRUNs are almost gone and system disk load is quite lower, what makes me think that bigger OS disk cache is making the difference here.
What now seems clear to me is that using the 8GB RBPi version makes a big difference when using big soundfonts, and this is against what i thought before these tests. I’m shocked, mates!! But it has sense, anyway, when you think twice about how the whole thing works.
That’s the sample amount kept in memory to be able to start playing the note immediately while loading the rest of the sample.
That value should be based on RAM available, not CPU type. If that’s a static build parameter, it shouldn’t vary based on CPU, but if it’s at runtime it should be based on RAM size or user-configurable.
So, the “attack” of the sample. Given we’re talking about bytes, this shouldn’t make any problems in any configuration (8192 bytes of let’s say even 3000 sample files each is not a thing we should worry about in terms of ram).